도입
지난 글에서 단건 반복 쿼리를 벌크 SELECT 쿼리로 변경함으로써 n + 1문제를 해결했다. 더 나아가 JMeter로 성능 테스트를 진행하여 얼만큼 성능이 높아졌는지 비교해보았다. 이번 글에서 실행 계획을 분석하고 쿼리를 튜닝한 뒤 다시 JMeter로 성능 테스트를 진행한 경험을 소개한다.
인덱스 생성과 인덱스 컨디션 푸시다운
n + 1 문제를 해결한 /api/v1/missions/matching 엔드포인트는 쿼리가 총 3번 전송된다.
아래는 첫 번째로 전송되는 쿼리이다. 미션(missions), 미션 카테고리(m_categories), 지역(regions), 미션 북마크(mission_bookmarks) 총 4개의 테이블을 조인하고 있다. 그리고 미션에 10만개, 미션 카테고리에 8개, 지역에 426개, 미션 북마크에 20만개의 더미 데이터를 넣어두었다.
select
m.id, m.title, m.price, m.mission_date, m.start_time, m.end_time, m.created_at,
m.category_id,mc.code, mc.name,
r.id,r.si,r.gu,r.dong,
m.bookmark_count, m.status,
mb.id
from missions m
join m_categories mc on mc.id = m.category_id
join regions r on m.region_id = r.id
left join mission_bookmarks mb on mb.mission_id = m.id and mb.user_id = :userId
where (m.is_deleted = 0) and m.citizen_id = :citizenId and m.status = 'MATCHING'
order by m.mission_date desc;
explain으로 실행 계획을 살펴보면, 테이블 m(missions)의 type 컬럼이 ALL인 것을 보아 풀 테이블 스캔을 했다. 큰 테이블에서 레코드 대부분을 읽을 경우 옵티마이저가 인덱스를 사용하지 않고 풀 테이블 스캔한다. 풀 테이블 스캔의 경우 순차 I/O를 사용하는데, 순차 I/O가 랜덤 I/O보다 빨리 많은 레코드를 읽어올 수 있다.
하지만 filtered 컬럼을 보면 0.13%으로 풀 테이블로 읽은 10만개의 레코드 중 99.87%의 레코드를 버렸다. 그리고 extra 칼럼을 보면, Using join buffer (hash join)이 적혀있다. 만약 조인을 수행될 때 드리븐 테이블의 조인 칼럼에 적절한 인덱스가 없으면 MySQL 서버의 조인 버퍼를 사용한다.
따라서 테이블 m에 적절한 인덱스가 없어 옵티마이저가 풀 테이블 스캔을 선택했고 조인 버퍼로 조인을 수행했음을 알 수 있다.

문제를 파악했으니 테이블 m(missions)에 적절한 인덱스를 생성해보자. where 절에 있는 컬럼 순서대로 인덱스를 생성해주고 다시 실행 계획을 살펴보았다.
rows 칼럼과 filtered 칼럼을 통해 생성한 인덱스(idx_missions)에서 조건에 맞는 18개의 레코드만 읽고 읽은 레코드를 모두 사용하고 있음을 알 수 있다.
create index idx_missions on missions(is_deleted, citizen_id, status);
다음으로 내부적인 처리 알고리즘에 대해 더 깊이 알 수 있게 extra 칼럼을 살펴보자. extra 칼럼에 Using where이 표시되었다. Using where은 MySQL 엔진이 스토리지 엔진으로부터 받은 레코드를 가공 또는 연산하는 작업을 수행했음을 나타내는 표시이다.
작업 범위 결정 조건은 스토리지 엔진 레벨에서 처리되지만 체크 조건은 MySQL 엔진 레이어에서 처리된다. where 절의 "m.status = 'MATCHING'"이 체크 조건이라 MySQL 엔진 레이어에서 처리 되므로 Using where 표시가 등장했음을 알 수 있다.

이 과정이 사소해 보여도 매우 비효율적인 작업을 수행하고 있어 성능을 크게 저하시킬 수 있다.
예를 들어 idx_missions 인덱스가 아래 표와 같다고 하자.
"m.is_deleted = 0 and m.citizen_id = 1"가 일치하는 레코드는 3개이고 실제 테이블을 읽어 3개의 레코드를 가져왔다. 하지만 그 중 "status = 'MATCHING'"에 일치하는 레코드는 1개 뿐이다. 우리는 디스크 I/O를 줄임으로써 쿼리의 성능을 높여야 함에도 불필요한 레코드 읽기가 발생한 것이다.
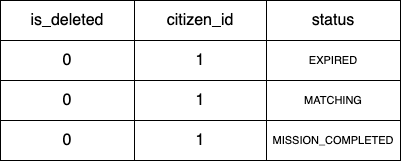
이를 개선하기 위해 MySQL 5.6부터 인덱스를 작업 범위 결정 조건으로 사용하지 못해도 인덱스에 포함된 칼럼의 조건이 있다면 모두 모아서 스토리지 엔진으로 전달할 수 있도록 인덱스 컨디션 푸시다운이 도입됐다.
아래 명령어로 인덱스 컨디션 푸시다운을 켜고 다시 실행계획을 살펴보면, extra 칼럼에 Using index condition이 표시된 것을 확인할 수 있다.
SET optimizer_switch='index_condition_pushdown=on';
인덱스를 이용한 정렬
정렬도 쿼리 성능 저하의 원인 중 하나이다.
우리가 튜닝하기 전, 첫 번째 쿼리의 실행계획을 다시 한 번 살펴보자.
테이블 mc의 extra 컬럼을 살펴보면, Using temporary; Using filesort가 표시됬음을 알 수 있다. 이는 조인한 결과를 임시 테이블에 저장한 뒤 메모리에서 Filesort라는 정렬 작업이 처리됬음을 나타낸다. 정렬 처리 방법 중 쿼리가 실행될 때 정렬해야할 레코드가 가장 많아 느리다.

하지만 where 절의 컬럼을 대상으로 인덱스(idx_missions)를 생성해주니 extra 컬럼에 Using filesort만 나타났다. 인덱스를 생성해줌으로써 테이블 m이 드라이빙 테이블이 되었다. 그리고 order by절을 살펴보면 "m.mission_date desc"로 드라이빙 테이블의 컬럼만 정렬 기준이 된다. 결국 조인한 뒤 조인 결과를 임시 테이블에 저장하는 과정이 필요없어지고 메모리에서 드라이빙 테이블만 정렬한다.
Filesort를 이용한 정렬은 쿼리가 실행될 때마다 정렬 작업이 메모리에서 수행된다는 단점이 있다. 따라서 order by 절에 대한 인덱스를 생성하면 쿼리가 실행될 때 이미 정렬돼 있어 순서대로 읽기만 하면 되어 매우 빠르다.
인덱스를 이용한 정렬을 위해 order by 절의 mission_date에 대해서 인덱스를 생성해주고 실행계획을 살펴보았다.
create index idx_missions_mission_date on missions(is_deleted, citizen_id, status, mission_date);
테이블 m의 extra 컬럼을 살펴보니 Using where; Backward index scan이 표시됐다. Backward index scan은 인덱스를 역순으로 읽는다는 뜻이다.
order by 절은 "m.mission_date desc"로 내림차순으로 정렬해야 한다. 하지만 인덱스가 오름차순으로 정렬되어 있어 옵티마이저가 인덱스를 역순으로 읽은 것이다. RealMySQL 8.0 8장에 따르면 InnoDB의 인덱스 페이지 내에서 레코드가 단방향으로 연결된 구조 때문에 역순 스캔이 정순 스캔에 비해 느리다고 한다. 그리고 역순으로 읽음으로써 인덱스 컨디션 푸시다운 기능을 사용하지 못하는 듯 하다.

MySQL 8.0에서 내림차순 인덱스를 지원해준다. 따라서 mission_date 컬럼을 내림차순으로 정렬한 인덱스를 생성해주자.
create index idx_missions_mission_date_desc on missions(is_deleted, citizen_id, status, mission_date desc);
다시 실행 계획을 살펴보면, 테이블 m의 extra 컬럼에 Using index condition만 나타났고 인덱스를 이용해 정렬을 처리했음을 알 수 있다.

커버링 인덱스
두 번째 쿼리는 첫 번째 쿼리와 마찬가지로 적절한 인덱스가 없어 풀 테이블 스캔을 하고 있어 where 절에 인덱스를 걸어주었다.
마지막으로 세 번째 쿼리를 튜닝해보자. 아래는 세 번째 쿼리로 미션 이미지(mission_images), 미션(missions)를 조인하고 있다.
select m.id, mi.path
from mission_images mi
join missions m on mi.mission_id=m.id
where mi.mission_id in :missionIds;
explain으로 실행계획을 살펴보면, 테이블 mi(mission_images)의 type 컬럼이 ALL인 것을 보아 풀 테이블 스캔을 하고 있다. 그리고 rows와 filtered를 통해 테이블에서 대략 50만건의 레코드를 읽고 필터링하여 50%의 레코드가 남았음을 알 수 있다.
그렇다면 대략 25만의 레코드가 조회되야 하는데 정작 조회된 컬럼은 132개였다. 이렇게 차이나는 이유는 무엇일까? MySQL 옵티마이저가 테이블과 인덱스에 대한 통계 정보를 토대로 실행 계획을 세우기 때문이다. 결국 MySQL 서버가 제대로된 통계 정보를 가지고 있지 않으면 이렇게 잘못된 예측을 한다.
이러한 단점을 보완하기 위해 히스토그램이 도입됐는데, 이에 대해서 나중에 다뤄보겠다.

실제로 where 조건에 맞는 레코드는 132건 뿐이었지만 풀 테이블 스캔하여 50만 건을 읽었다. 따라서 where 절의 컬럼에 대해 인덱스를 생성해주고 다시 실행계획을 살펴보았다.
create index idx_mission_images on mission_images(mission_id);
테이블 mi의 key 컬럼을 통해 옵티마이저가 제대로 idx_mission_images를 사용하고 있음을 알 수 있다.

이제 더 나아가서 커버링 인덱스를 적용해보자.
커버링 인덱스란 데이터 파일을 전혀 읽지 않고 인덱스만 읽어서 쿼리를 모두 처리하는 것을 뜻한다. 인덱스를 이용할 때 가장 큰 부하를 차지하는 부분은 인덱스 검색에서 일치하는 레코드를 읽기 위해 데이터 파일을 검색하는 작업이다. 최악의 경우 인덱스를 통해 검색된 결과 레코드를 한 건 한 건마다 디스크를 한 번 씩 읽어야 할 수도 있다. 이때 랜덤 I/O가 많이 발생해 성능이 저하된다.
select를 보면, mission_images의 path 컬럼만 조회되고 있다. path 컬럼에 대해서도 인덱스를 걸어주었다.
create index idx_mission_images on mission_images(mission_id, path);
다시 explain으로 실행계획을 살펴보자. 테이블 mi의 extra 컬럼에 Using index가 표시됐다. 이를 통해 커버링 인덱스가 잘 적용됐음을 알 수 있다.

성능 테스트
/api/v1/missions/matching 엔드포인트에서 발생하는 3번의 쿼리를 모두 튜닝했다.
마지막으로 JMeter로 성능 테스트를 진행해보자. 지난 글, n + 1 문제를 벌크(bulk) SELECT 쿼리로 해결하기 에서 n + 1문제를 해결하고 JMeter로 성능 테스트한 환경과 동일하다.
100명의 유저가 100초 동안 생성되고 요청을 10번 반복하는 테스트를 진행한 결과, 평균 응답속도가 333ms로 94.32%만큼 성능이 향상되었다.

후기
첫 쿼리 튜닝 경험을 이렇게 글로 옮기게 되었다. RealMySQL 8.0 1권을 열심히 읽어서 이론을 익히고 실전에 돌입했는데 정말 재밌는 경험이었다😆
그리고 슬로우 쿼리를 튜닝한 것만으로도 성능이 굉장히 향상되어 놀라웠다. 성능 개선 경험을 더 가져봐야겠다.
참고
- RealMySQL 8.0
'프로젝트 > 트러블슈팅' 카테고리의 다른 글
| n + 1 문제를 IN절로 해결하기 (0) | 2024.02.12 |
|---|---|
| 리팩토링을 통한 복잡했던 모듈 구조를 단순화 (0) | 2024.02.06 |
| 레이어별 멀티 모듈 적용 (과도한 모듈 분리로 실패🤪) (0) | 2024.01.15 |
| 랭킹 조회에 로컬 캐시 적용하기 (1) | 2024.01.08 |
| Testcontainers로 통합 테스트 환경 만들기 (+ Testcontainers를 Spring Bean으로 등록) (1) | 2023.12.28 |



